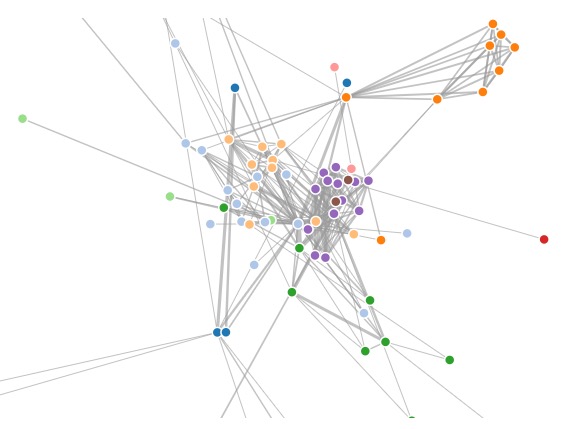
t-SNE
note
许多真实世界的数据集具有较低的内在维度,但是它们嵌入在高维空间中,人类因为受限于三维可视化,而不易发现这些内在的结构
t分布式随机邻域嵌入(t-SNE):t-distributed stochastic neighbor embedding (t-SNE), 是一种非常流行的非线性降为的方法,它和 PCA的不同之处在于:
PCA的本质是在降维之后尽量保存矩阵的最大变异性,而实际上我们经常是想保存原本的结构,换句话说,就是降维前各个点相对距离结构在降维之后要继续保留下来
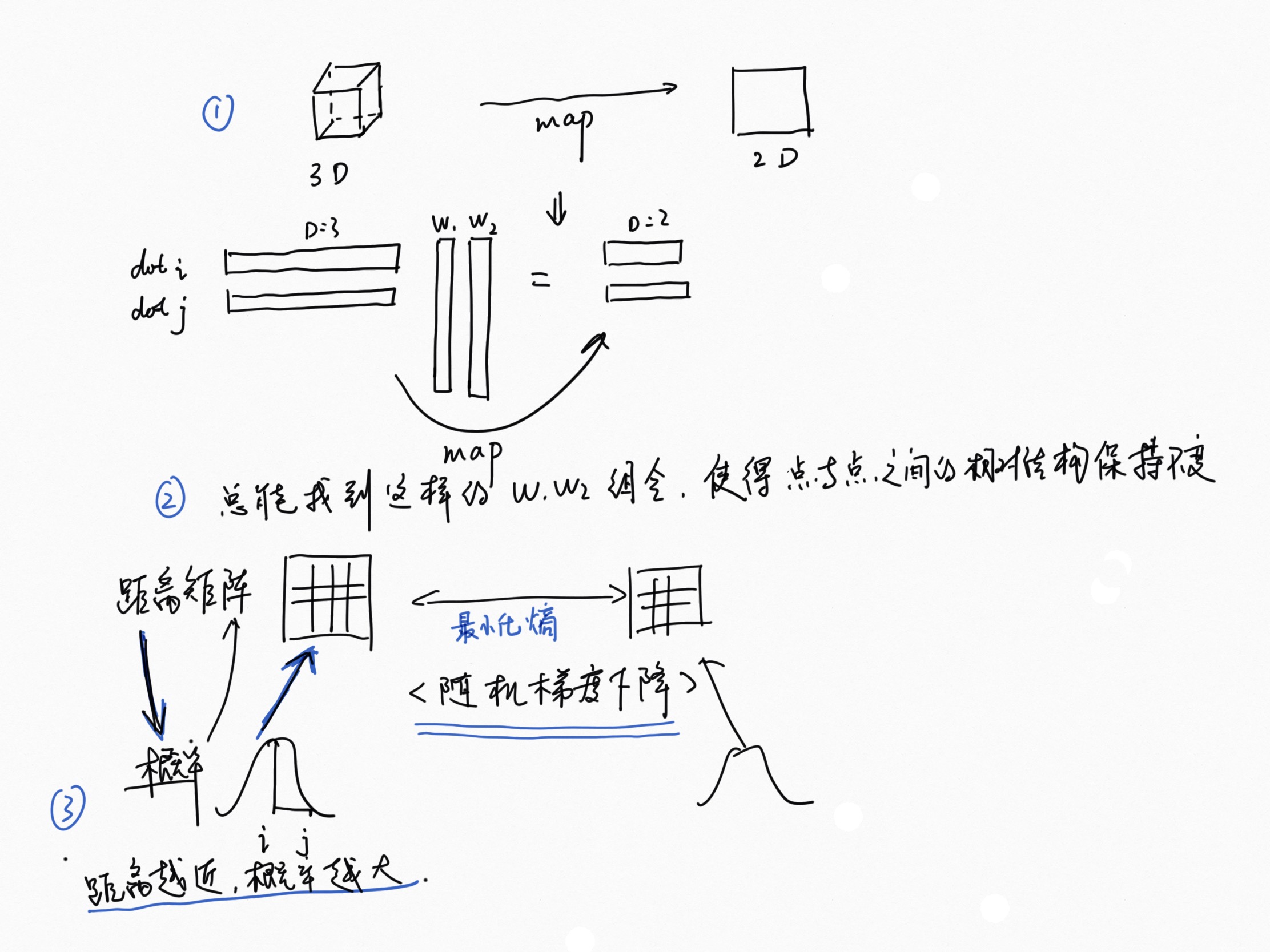
过程
我们这里用 3维代替高维, 2维代替低维 那么3维的点经过 映射之后 在2维的空间 要保存原有的相对距离结构
这个过程本质 神经网络深度学习问题,是找到最佳的映射矩阵(最好的 w1 w2 组合方式),使得映射后,数据结构得以保存 那么怎么来衡量数据结构保存的效果?
那就看比较原始数据下的距离矩阵 和 映射后的距离矩阵 的差 这样的话问题就转化为: 求熵最小化的问题?
那么这里有个问题,高维度的距离矩阵怎么和低维的距离矩阵进行比较呢 ? 这就是 t-SNE 的特殊的地方:它把距离问题转换为概率问题,距离越近的i,j两点,pij越大, 以i为中心的t分布,描述 i 与所有点的距离,
之所以不用正态分布,是因为t分布是长尾 的,这样的分布在尾部的数据点之间(距离较远的点)的惩罚不是区分的很严格,
换句话说就是 映射后 近变远 的惩罚系数 > 远变近的惩罚系数,
这个过程可以想象成 一个弹簧产生形变,映射由远变进就是压缩,会产生斥力,映射由近变远,就会拉伸,产生引力 ,形变就好像是熵,是映射前和映射后的差距,产生的单位力(力/形变长度) 的绝对值就好像是惩罚系数,拉伸的形变产生的单位引力 > 压缩的形变产生的单位斥力 ,
这就很好的解决了数据点映射后的拥挤问题,就好像点与点之间有一定的斥力(为了纠正远变近的情况),但是这个斥力系数又小于点与点之间的引力, 这样在纠正同样误差的时候我们会优先纠正近的变成远的, 体现在单位引力大于单位斥力(为了纠正近变远的情况,单位引力大于单位斥力是因为我们更在乎点与点之间相似的机构 , 可以想象最后每个点会在所有合力的情况下达到一个平衡, 如下图: